Human Gene S100A10 (ENST00000368811.8_7) from GENCODE V47lift37
Description: S100 calcium binding protein A10 (from RefSeq NM_002966.3)Gencode Transcript: ENST00000368811.8_7Gencode Gene: ENSG00000197747.9_9Transcript (Including UTRs) Position: hg19 chr1:151,955,391-151,966,335 Size: 10,945 Total Exon Count: 3 Strand: -Coding Region Position: hg19 chr1:151,955,639-151,958,706 Size: 3,068 Coding Exon Count: 2
Data last updated at UCSC: 2024-08-22 23:36:26
Sequence and Links to Tools and Databases
Comments and Description Text from UniProtKB
ID: S10AA_HUMAN DESCRIPTION: RecName: Full=Protein S100-A10; AltName: Full=Calpactin I light chain; AltName: Full=Calpactin-1 light chain; AltName: Full=Cellular ligand of annexin II; AltName: Full=S100 calcium-binding protein A10; AltName: Full=p10 protein; AltName: Full=p11;FUNCTION: Because S100A10 induces the dimerization of ANXA2/p36, it may function as a regulator of protein phosphorylation in that the ANXA2 monomer is the preferred target (in vitro) of tyrosine- specific kinase.SUBUNIT: Heterotetramer containing 2 light chains of S100A10/p11 and 2 heavy chains of ANXA2/p36. Interacts with SCN10A (By similarity).MISCELLANEOUS: Does not appear to bind calcium. Contains 2 ancestral calcium site related to EF-hand domains that have lost their ability to bind calcium.SIMILARITY: Belongs to the S-100 family.WEB RESOURCE: Name=Atlas of Genetics and Cytogenetics in Oncology and Haematology; URL="http://atlasgeneticsoncology.org/Genes/S100A10ID44145ch1q21.html";
Primer design for this transcript
MalaCards Disease Associations
Comparative Toxicogenomics Database (CTD)
The following chemicals interact with this gene
C049325
1,2-dithiol-3-thione
D000082
Acetaminophen
D001564
Benzo(a)pyrene
D002251
Carbon Tetrachloride
D019327
Copper Sulfate
D004958
Estradiol
D004997
Ethinyl Estradiol
D005557
Formaldehyde
D010634
Phenobarbital
D013749
Tetrachlorodibenzodioxin
D014635
Valproic Acid
C017947
sodium arsenite
C111118
2',3,3',4',5-pentachloro-4-hydroxybiphenyl
C029497
2,3-bis(3'-hydroxybenzyl)butyrolactone
C016403
2,4-dinitrotoluene
C023514
2,6-dinitrotoluene
D015081
2-Naphthylamine
C023035
3,4,5,3',4'-pentachlorobiphenyl
C472791
3-(4'-hydroxy-3'-adamantylbiphenyl-4-yl)acrylic acid
C017906
3-dinitrobenzene
C009505
4,4'-diaminodiphenylmethane
D015123
7,8-Dihydro-7,8-dihydroxybenzo(a)pyrene 9,10-oxide
D016604
Aflatoxin B1
D000452
Aldrin
D000643
Ammonium Chloride
D001205
Ascorbic Acid
D001554
Benzene
D001663
Bilirubin
D019256
Cadmium Chloride
D002117
Calcitriol
D002945
Cisplatin
D002994
Clofibrate
D002995
Clofibric Acid
D003375
Coumestrol
D016572
Cyclosporine
D003561
Cytarabine
D003993
Dibutyl Phthalate
D004026
Dieldrin
D004041
Dietary Fats
D004051
Diethylhexyl Phthalate
D004052
Diethylnitrosamine
D004137
Dinitrochlorobenzene
D004237
Diuron
D011345
Fenofibrate
D005419
Flavonoids
D005472
Fluorouracil
D005492
Folic Acid
D005839
Gentamicins
D058185
Magnetite Nanoparticles
D016685
Mitomycin
D009538
Nicotine
D010672
Phenytoin
D011374
Progesterone
D004113
Succimer
D013739
Testosterone
D014212
Tretinoin
D014241
Trichloroethylene
D014640
Vancomycin
D014752
Vinyl Chloride
C006632
arsenic trioxide
C015001
arsenite
C095105
bexarotene
C043211
carvedilol
C014347
decitabine
C056933
fumonisin B1
C039281
furan
C008261
lead acetate
C045621
miglitol
C028577
monobutyl phthalate
C017096
n-butoxyethanol
C029938
nickel sulfate
C014707
nitrosobenzylmethylamine
C041786
palm oil
C058305
phenethyl isothiocyanate
C006253
pirinixic acid
C045950
propiconazole
C012589
trichostatin A
C025643
vinclozolin
C111237
vorinostat
Common Gene Haplotype Alleles
Press "+" in the title bar above to open this section.
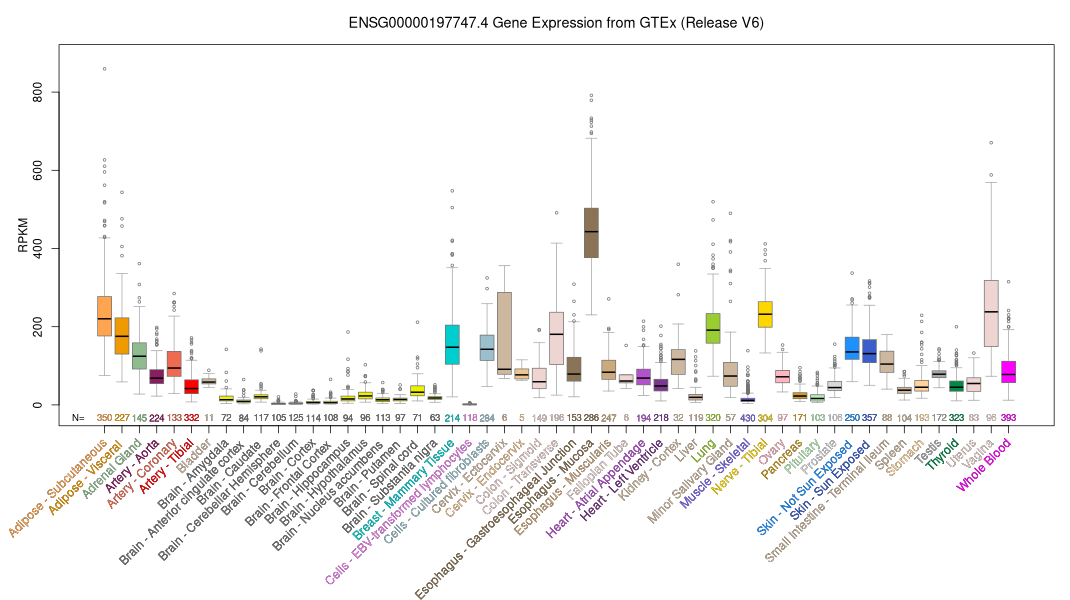
RNA-Seq Expression Data from GTEx (53 Tissues, 570 Donors)
Microarray Expression Data
Press "+" in the title bar above to open this section.
mRNA Secondary Structure of 3' and 5' UTRs
Vienna RNA Package is used to perform the secondary structure predictions and folding calculations. The estimated folding energy is in kcal/mol. The more negative the energy, the more secondary structure the RNA is likely to have.
Protein Domain and Structure Information
InterPro Domains: Graphical view of domain structure IPR011992 - EF-hand-like_domIPR001751 - S100/CaBP-9k_CSIPR013787 - S100_Ca-bd_subPfam Domains: PF01023 - S-100/ICaBP type calcium binding domainSCOP Domains: 47473 - EF-handProtein Data Bank (PDB) 3-D Structure ModBase Predicted Comparative 3D Structure on P60903 The pictures above may be empty if there is no ModBase structure for the protein. The ModBase structure frequently covers just a fragment of the protein. You may be asked to log onto ModBase the first time you click on the pictures. It is simplest after logging in to just click on the picture again to get to the specific info on that model.
Orthologous Genes in Other Species
Orthologies between human, mouse, and rat are computed by taking the best BLASTP hit, and filtering out non-syntenic hits. For more distant species reciprocal-best BLASTP hits are used. Note that the absence of an ortholog in the table below may reflect incomplete annotations in the other species rather than a true absence of the orthologous gene.
Gene Ontology (GO) Annotations with Structured Vocabulary
Descriptions from all associated GenBank mRNAs
LF206217 - JP 2014500723-A/13720: Polycomb-Associated Non-Coding RNAs.BC105786 - Homo sapiens S100 calcium binding protein A10, mRNA (cDNA clone MGC:111133 IMAGE:6701084), complete cds.BC015973 - Homo sapiens S100 calcium binding protein A10, mRNA (cDNA clone MGC:23737 IMAGE:4103596), complete cds.M81457 - Human calpactin 1 light chain mRNA, complete cds.M38591 - Homo sapiens cellular ligand of annexin II (p11) mRNA, complete cds.AK291073 - Homo sapiens cDNA FLJ77627 complete cds, highly similar to Homo sapiens S100 calcium binding protein A10 (annexin II ligand, calpactin I, light polypeptide (p11)) (S100A10), mRNA.JD281190 - Sequence 262214 from Patent EP1572962.JD239533 - Sequence 220557 from Patent EP1572962.LF352442 - JP 2014500723-A/159945: Polycomb-Associated Non-Coding RNAs.LF352441 - JP 2014500723-A/159944: Polycomb-Associated Non-Coding RNAs.DQ893555 - Synthetic construct clone IMAGE:100006185; FLH195068.01X; RZPDo839F0483D S100 calcium binding protein A10 (annexin II ligand, calpactin I, light polypeptide (p11)) (S100A10) gene, encodes complete protein.DQ893556 - Synthetic construct clone IMAGE:100006186; FLH195069.01X; RZPDo839G0483D S100 calcium binding protein A10 (annexin II ligand, calpactin I, light polypeptide (p11)) (S100A10) gene, encodes complete protein.DQ893557 - Synthetic construct clone IMAGE:100006187; FLH195070.01X; RZPDo839H0483D S100 calcium binding protein A10 (annexin II ligand, calpactin I, light polypeptide (p11)) (S100A10) gene, encodes complete protein.KJ897512 - Synthetic construct Homo sapiens clone ccsbBroadEn_06906 S100A10 gene, encodes complete protein.DQ896803 - Synthetic construct Homo sapiens clone IMAGE:100011263; FLH195064.01L; RZPDo839B0483D S100 calcium binding protein A10 (annexin II ligand, calpactin I, light polypeptide (p11)) (S100A10) gene, encodes complete protein.DQ896804 - Synthetic construct Homo sapiens clone IMAGE:100011264; FLH195066.01L; RZPDo839D0483D S100 calcium binding protein A10 (annexin II ligand, calpactin I, light polypeptide (p11)) (S100A10) gene, encodes complete protein.AB464694 - Synthetic construct DNA, clone: pF1KB8860, Homo sapiens S100A10 gene for S100 calcium binding protein A10, without stop codon, in Flexi system.CR542162 - Homo sapiens full open reading frame cDNA clone RZPDo834A0524D for gene S100A10, S100 calcium binding protein A10 (annexin II ligand, calpactin I, light polypeptide (p11)); complete cds, without stopcodon.LF352440 - JP 2014500723-A/159943: Polycomb-Associated Non-Coding RNAs.LF352439 - JP 2014500723-A/159942: Polycomb-Associated Non-Coding RNAs.LF352438 - JP 2014500723-A/159941: Polycomb-Associated Non-Coding RNAs.D28387 - Homo sapiens mRNA for calpactin I light chain, 5'UTR region.MA588019 - JP 2018138019-A/159945: Polycomb-Associated Non-Coding RNAs.MA588018 - JP 2018138019-A/159944: Polycomb-Associated Non-Coding RNAs.MA588017 - JP 2018138019-A/159943: Polycomb-Associated Non-Coding RNAs.MA588016 - JP 2018138019-A/159942: Polycomb-Associated Non-Coding RNAs.MA588015 - JP 2018138019-A/159941: Polycomb-Associated Non-Coding RNAs.MA441794 - JP 2018138019-A/13720: Polycomb-Associated Non-Coding RNAs.
Other Names for This Gene
Alternate Gene Symbols: A8K4V8, ANX2LG, CAL1L, CLP11, ENST00000368811.1, ENST00000368811.2, ENST00000368811.3, ENST00000368811.4, ENST00000368811.5, ENST00000368811.6, ENST00000368811.7, NM_002966, P08206, P60903, Q5T1C5, S10AA_HUMAN, uc318hbu.1, uc318hbu.2UCSC ID: ENST00000368811.8_7RefSeq Accession: NM_002966.3 Protein: P60903
(aka S10AA_HUMAN or S110_HUMAN)
Gene Model Information
Click here
for a detailed description of the fields of the table above.
Methods, Credits, and Use Restrictions
Click here
for details on how this gene model was made and data restrictions if any.
 Sequence and Links to Tools and Databases
Sequence and Links to Tools and Databases  Common Gene Haplotype Alleles
Common Gene Haplotype Alleles